

El perceptrón dentro del campo de las redes neuronales tiene dos acepciones. Puede referirse a un tipo de red neuronal artificial desarrollada por Frank Rosenblatt y, dentro de esta teoría emitida por Rosenblatt, también puede entenderse como la neurona artificial o unidad básica de inferencia en forma de discriminador lineal, a partir de lo cual se desarrolla un algoritmo capaz de generar un criterio para seleccionar un sub-grupo a partir de un grupo de componentes más grande. La limitación de este algoritmo es que si dibujamos en un plot estos elementos, se deben poder separar con un hiperplano únicamente los elementos “deseados” discriminándolos (separándolos) de los “no deseados”. El perceptrón puede utilizarse con otros perceptrones u otro tipo de neurona artificial, para formar redes neuronales más complicadas.
El perceptrón usa una matriz para representar las redes neuronales y es un discriminador terciario que traza su entrada X (un vector binario) a un único valor de salida f(x) (un solo valor binario) a través de dicha matriz.

Donde W es un vector de pesos reales y W ⋅ X es el producto escalar (que computa una suma ponderada). U es el ‘umbral’, el cual representa el grado de inhibición de la neurona, es un término constante que no depende del valor que tome la entrada.
El valor de f(x) (0 o 1) se usa para clasificar X como un caso positivo o un caso negativo, en el caso de un problema de clasificación binario. El umbral puede pensarse de como compensar la función de activación, o dando un nivel bajo de actividad a la neurona del rendimiento. La suma ponderada de las entradas debe producir un valor mayor que U para cambiar la neurona de estado 0 a 1.
Aprendizaje
En el perceptrón, existen dos tipos de aprendizaje, el primero utiliza una tasa de aprendizaje mientras que el segundo no la utiliza. Esta tasa de aprendizaje amortigua el cambio de los valores de los pesos.
El algoritmo de aprendizaje es el mismo para todas las neuronas, todo lo que sigue se aplica a una sola neurona en el aislamiento. Se definen algunas variables primero:
- El x(j) denota el elemento en la posición J en el vector de la entrada.
- El w(j) el elemento en la posición J en el vector de peso.
- El Y denota la salida de la neurona.
- El δ denota la salida esperada.
- El α es una constante tal que 0 < α < 1
Los dos tipos de aprendizaje difieren en este paso. Para el primer tipo de aprendizaje, utilizando tasa de aprendizaje, utilizaremos la siguiente regla de actualización de los pesos:
- w(j)′ = w(j) + α(δ − y) x(j)
Para el segundo tipo de aprendizaje, sin utilizar tasa de aprendizaje, la regla de actualización de los pesos será la siguiente:
- w(j)′ = w(j) + (δ − y) x(j)
Por lo cual, el aprendizaje es modelado como la actualización del vector de peso después de cada iteración, lo cual sólo tendrá lugar si la salida Y difiere de la salida deseada δ. Para considerar una neurona al interactuar en múltiples iteraciones debemos definir algunas variables más:
- Xi denota el vector de entrada para la iteración i
- Wi denota el vector de peso para la iteración i
- Yi denota la salida para la iteración i
- Dm = {(x1, y1), … ,(xm, ym)} denota un periodo de aprendizaje de M iteraciones.
En cada iteración el vector de peso es actualizado como sigue:
- Para cada pareja ordenada (X, Y) en Dm = {(X1, Y1), … ,(Xm, Ym)}
- Pasar (Xi, Yi, Wi) a la regla de actualización w(j)′ = w(j) + α(δ − Y) x(j)
El periodo de aprendizaje Dm se dice que es separable linealmente si existe un valor positivo Y y un vector de peso W tal que: Yi ⋅ (⟨W, Xi⟩ + U) > Y para todos los i.
Novikoff probó que el algoritmo de aprendizaje converge después de un número finito de iteraciones si los datos son separables linealmente y el número de errores está limitado a:

Sin embargo si los datos no son separables linealmente, la línea de algoritmo anterior no se garantiza que converja.
Perceptrón multicapa
El perceptrón multicapa es una red neuronal artificial formada por múltiples capas, esto le permite resolver problemas que no son linealmente separables, lo cual es la principal limitación del perceptrón. El perceptrón multicapa puede ser totalmente o localmente conectado. En el primer caso cada salida de una neurona de la capa “i” es entrada de todas las neuronas de la capa “i+1”, mientras que en el segundo cada neurona de la capa “i” es entrada de una serie de neuronas (región) de la capa “i+1”.
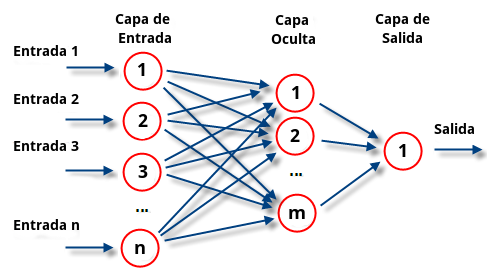
Las capas pueden clasificarse en tres tipos:
- Capa de entrada: Constituida por aquellas neuronas que introducen los patrones de entrada en la red. En estas neuronas no se produce procesamiento.
- Capas ocultas: Formada por aquellas neuronas cuyas entradas provienen de capas anteriores y cuyas salidas pasan a neuronas de capas posteriores.
- Capa de salida: Neuronas cuyos valores de salida se corresponden con las salidas de toda la red.
La propagación hacia atrás (también conocido como retropropagación del error o regla delta generalizada), es un algoritmo utilizado en el entrenamiento de estas redes, por ello, el perceptrón multicapa también es conocido como red de retropropagación.
Limitaciones:
- El Perceptrón Multicapa no extrapola bien, es decir, si la red se entrena mal o de manera insuficiente, las salidas pueden ser imprecisas.
- La existencia de mínimos locales en la función de error dificulta considerablemente el entrenamiento, pues una vez alcanzado un mínimo el entrenamiento se detiene aunque no se haya alcanzado la tasa de convergencia fijada.
Cuando caemos en un mínimo local sin satisfacer el porcentaje de error permitido se puede considerar: cambiar la topología de la red (número de capas y número de neuronas), comenzar el entrenamiento con unos pesos iniciales diferentes, modificar los parámetros de aprendizaje, modificar el conjunto de entrenamiento o presentar los patrones en otro orden.