
Esta es una traducción del artículo original publicado en el blog de Mozilla Hacks. Traducción por Sergio Carlavilla Delgado.
En octubre del año pasado Mozilla anunció el Proyecto Quantum – nuestra iniciativa para crear un motor de navegación web de nueva generación. Ya estamos en marcha con el proyecto. De hecho liberamos nuestra primera pieza significativa de Quantum con Firefox 53.
Pero sabemos que para personas que no construyen navegadores web (¡y eso es la mayoría de la gente!), puede ser difícil ver por qué algunos de los cambios que estamos realizando en Firefox son tan importantes. Después de todo, muchos de los cambios que estamos haciendo serán invisibles para los usuarios.
Con esto en mente, estamos lanzando una serie de publicaciones para proporcionar una visión más profunda de lo que estamos haciendo con el proyecto Quantum. Esperamos que esta serie de publicaciones te brinde una mejor comprensión de cómo funciona Firefox y las formas en que Firefox está construyendo un motor de navegación web de nueva generación para mejor aprovechar el hardware de los ordenadores modernos.
Para comenzar esta serie de publicaciones, creemos que es mejor comenzar por explicar el aspecto fundamental que Quantum está cambiando.
¿Qué es un motor de navegación web y cómo funciona?
Si vamos a empezar por algún lado, debemos empezar desde el principio.
Un navegador web es una pieza de software que carga archivos (normalmente de un servidor remoto) y los muestra localmente, permitiendo la interacción del usuario.
Quantum es el nombre clave para un proyecto que hemos emprendido en Mozilla para actualizar masivamente la parte de Firefox que calcula qué mostrar a los usuarios basándose en esos archivos remotos. El término que utiliza la industria para esta parte es “motor web”, y sin uno, estarías leyendo código fuente en lugar de ver realmente un sitio web. El motor web de Firefox se llama Gecko.
Es bastante fácil ver al motor web como una caja negra, algo así como una TV: los datos entran, y la caja negra calcula qué mostrar en la pantalla para representar esos datos. La pregunta de hoy es: ¿cómo? ¿Cuáles son los pasos que convierten los datos en las páginas web que vemos?

Los datos que componen una página web son muchas cosas, pero se desglosan principalmente en 3 partes:
- código que representa la estructura de una página web
- código que proporciona estilo: el aspecto visual de la estructura
- código que actúa como un script de acciones que el navegador puede tomar: computación, reaccionar a las acciones del usuario, y modificar la estructura y el estilo más allá de lo que se cargó inicialmente.
El motor del navegador web combina la estructura y el estilo para dibujar la página web en tu pantalla y averiguar qué partes son interactivas.
Todo comienza con la estructura. Cuando se le pide a un navegador web que cargue un sitio web, se le da una dirección. En esta dirección se encuentra otra computadora que, cuando es contactada, enviará los datos de vuelta al navegador web. Los detalles de cómo esto ocurre es un artículo completo en sí mismo, pero al final el navegador tiene los datos. Estos datos son enviados en un formato denominado HTML, y este describe la estructura de la página web. ¿Cómo entiende un navegador web HTML?
El motor del navegador web contiene fragmentos especiales de código llamados parsers que convierten los datos de un formato en otro que el navegador web mantiene en su memoria. El parser de HTML toma el HTML, algo así como:
<section> <h1 class="main-title">Hello!</h1> <img src="http://example.com/image.png"> </section>
Y lo analiza, entendiendo:
Bien, hay una sección. Dentro de la sección se encuentra un título de nivel 1, que contiene el texto: “Hello!”. También hay una imagen dentro de la sección. Puedo encontrar los datos de la imagen en la ubicación: http://example.com/image.png
La estructura almacenada en memoria de la página web se denomina Modelo de Objeto de Documento o DOM (Document Object Model). A diferencia de un texto largo, el DOM representa un árbol de elementos de la página web final: las propiedades de los elementos individuales y qué elementos están dentro de otros elementos.

Además de describir la estructura de la página, el HTML también incluye direcciones donde se pueden encontrar estilos y scripts. Cuando el navegador los encuentra, se pone en contacto con esas direcciones y carga sus datos. Esos datos alimentan a otros parsers que están especializados en esos tipos de datos. Si se encuentran scripts, pueden modificar la estructura y el estilo de la página antes de que haya finalizado el parseo del archivo. El formato de estilo, CSS, juega el siguiente papel en nuestro motor del navegador web.
Con estilo
CSS es un lenguaje de programación que permite a los desarrolladores describir la apariencia de elementos particulares en una página. CSS significa “hojas de estilo en cascada”, denominado así porque permite múltiples conjuntos de instrucciones de estilo, donde las instrucciones pueden sobreescribir las instrucciones anteriores o más generales (llamado cascada). Un poco de CSS podría tener el siguiente aspecto:
section {
font-size: 15px;
color: #333;
border: 1px solid blue;
}
h1 {
font-size: 2em;
}
.main-title {
font-size: 3em;
}
img {
width: 100%;
}
CSS se divide en gran parte en agrupaciones llamadas reglas, que constan de dos partes. La primera parte son los selectores. Los selectores describen los elementos del DOM (¿recuerdas los de arriba?) a los que se les está aplicando los estilos y una lista de declaraciones que especifican los estilos que se aplicarán a los elementos que coincidan con el selector. El motor del navegador web contiene un subsistema llamado motor de estilos cuyo trabajo es tomar el código CSS y aplicarlo al DOM que fue creado por el parser HTML.

Por ejemplo, en el CSS anterior, tenemos una regla que hace referencia al selector “section”, que coincidirá con cualquier elemento en el DOM con ese nombre. Entonces se hacen anotaciones de estilo para cada elemento en el DOM. Eventualmente, cada elemento en el DOM termina teniendo un estilo y llamamos a este estado el estilo computado para ese elemento. Cuando se aplican múltiples estilos que compiten sobre el mismo elemento, los que vienen después o son más específicos ganan. Piensa en las hojas de estilo como en el papel de trazado fino; cada capa puede cubrir las capas anteriores, pero también permite que se muestren las capas inferiores.
Una vez el motor del navegador web ha computado los estilos, ¡es hora de ponerlo en uso! El DOM y los estilos computados son introducidos en un motor de diseño que tiene en cuenta el tamaño de la ventana que se est´ dibujando. El motor de diseño utiliza varios algoritmos para tomar cada elemento y dibujar una caja que incluya su contenido y tenga en cuenta todos los estilos que se le aplican.
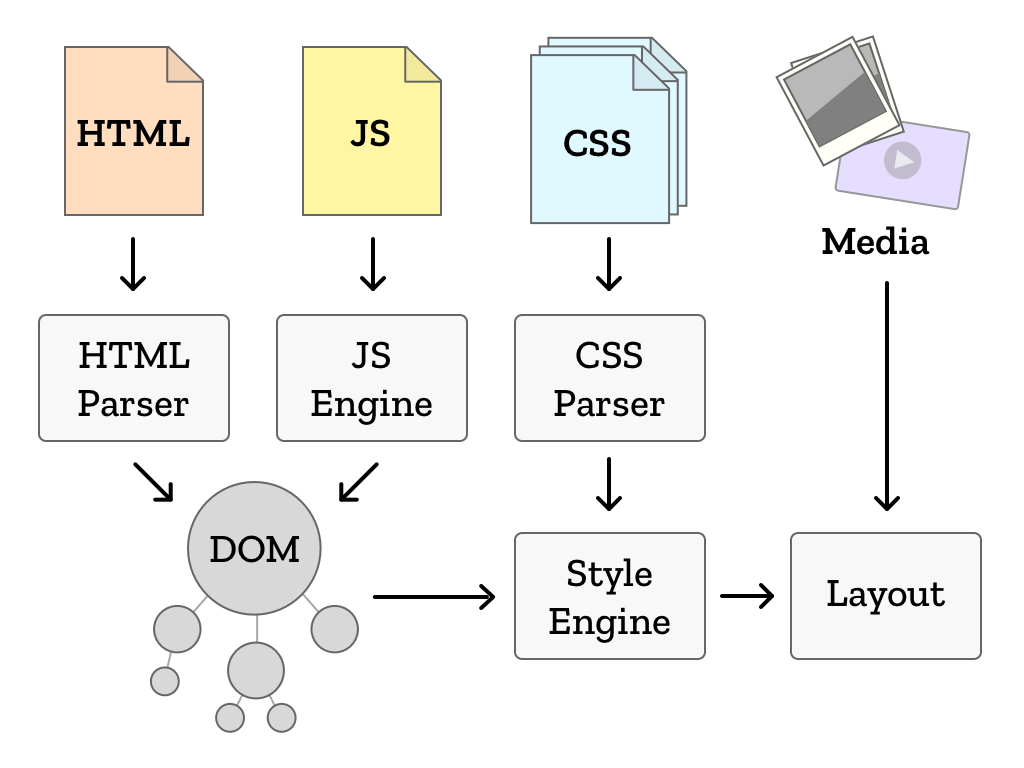
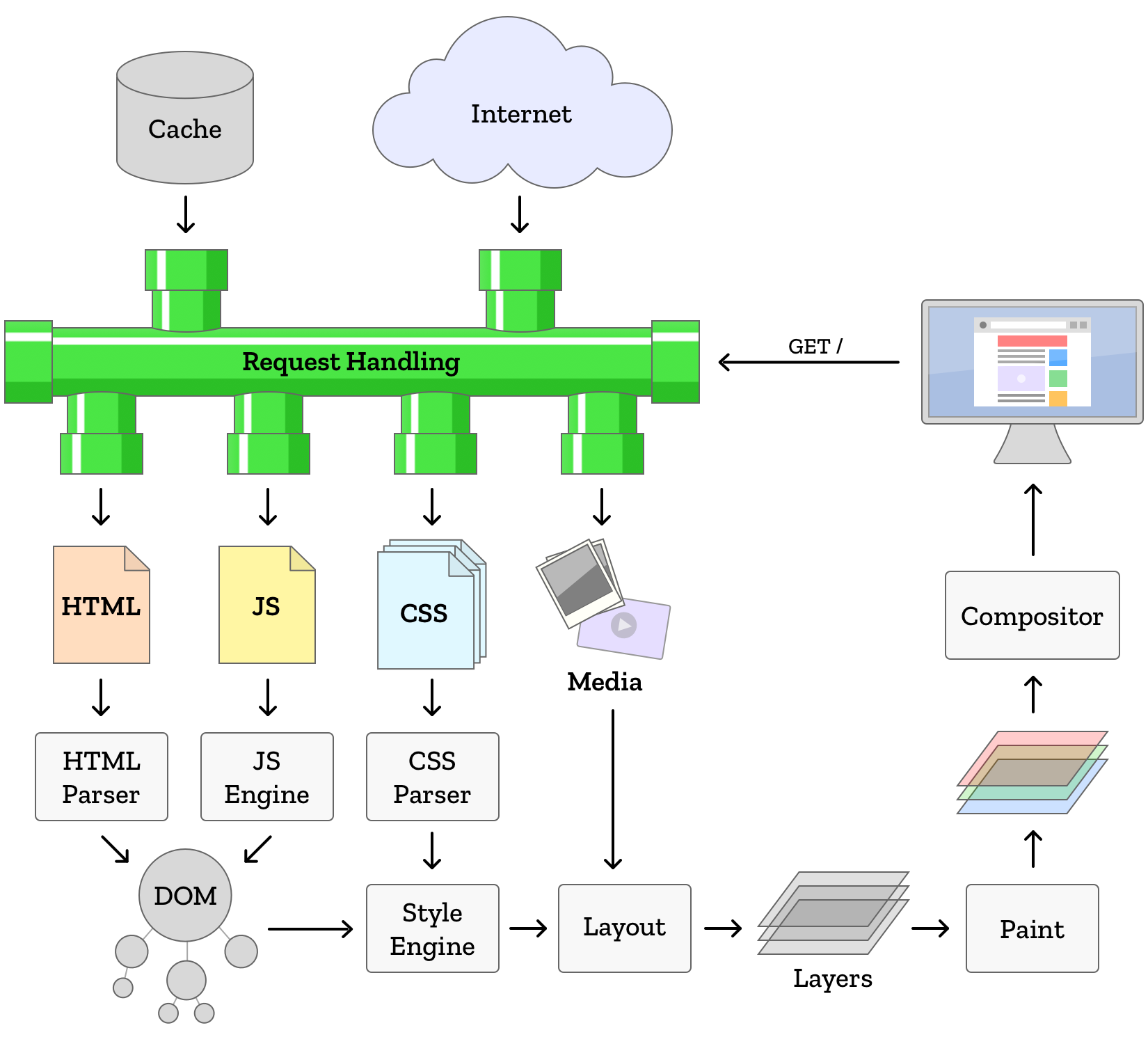
Cuando el diseño esta completo, es el momento de convertir el esquema de la página en la parte que tú ves. Este proceso se conoce como dibujado, y es la combinación final de todos los pasos previos. Cada caja definida se dibuja, llena del contenido del DOM y con los estilos del CSS. Ahora el usuario ve la página, reconstruida a partir del código que la define.
¡Esto solía ser todo lo que sucedía!
Cuando el usuario desplaza la página, volveremos a dibujar, para mostrar las partes nuevas de la página que estaban anteriormente fuera de la ventana. ¡Resulta, sin embargo, que a los usuarios les encanta desplazar la página! El motor del navegador web sabe con bastante seguridad que se le pedirá que muestre contenido fuera de la ventana inicial que ha dibujado (llamada ventana de visualización o viewport). Los navegadores más modernos aprovechan este hecho y dibujan más página de la que está visible inicialmente. Cuando el usuario se desplaza, las partes de la página que quiere ver ya están dibujadas y listas. Como resultado, el desplazamiento es más rápido y fluido. Esta técnica es la base de la composición, que es un término para las técnicas que reducen la cantidad de pintados requeridos.
Además, algunas veces necesitamos volver a dibujar partes de la pantalla. Tal vez el usuario esté viendo un vídeo que se reproduce a 60 cuadros por segundo. O tal vez hay una presentación de diapositivas o una lista animada en la página. Los navegadores pueden detectar qué partes de la página se moverán o actualizarán, y en lugar de pintar toda la página, crean una capa para contenerlo. Una página puede estar formada por muchas capas que se superponen entre sí. Una capa puede cambiar de posición, desplazamiento, transparencia o moverse detrás o delante de otras capas, ¡sin tener que volver a pintar nada! Bastante conveniente.
A veces, un script o una animación cambia el estilo de un elemento. Cuando esto ocurre, el motor de estilo necesita volver a calcular el estilo del elemento (y potencialmente el estilo de muchos más elementos de la página), recalcular el diseño y volver a dibujar la página. Esto lleva mucho tiempo en términos de velocidad de computadora, pero siempre que ocurra de manera ocasional, el proceso no afectará negativamente la experiencia del usuario.
En las aplicaciones web modernas, la estructura del documento en sí misma es modificada frecuentemente por los scripts. Esto podría requerir que todo el proceso de diseño comience más o menos desde cero, con el HTML siendo analizado en el DOM, computar el estilo, reflujo y dibujado.
Estándares
No todos los navegadores web interpretan HTML, CSS y JavaScript de la misma forma. El efecto puede variar: desde pequeñas diferencias visuales hasta el sitio web ocasional que funciona en una navegador y en no en otro. Actualmente, en la Web moderna, la mayoría de los sitios web parecen funcionar independientemente del navegador que elija. ¿Cómo logran los navegadores este nivel de consistencia?
Los formatos del código de sitios web, así como las reglas que rigen la forma en que el código se interpreta y se convierte en una página visual interactiva, se definen mediante documentos mutuamente acordados denominados estándares. Estos documentos son desarrollados por comités que constan de representantes de los fabricantes de los navegadores web, desarrolladores web, diseñadores y otros miembros de la industria. Juntos determinan el comportamiento preciso que el motor del navegador web debería exhibir dada una pieza especifica de código. Existen estándares para HTML, CSS y JavaScript, así como los formatos de datos de imágenes, vídeo, audio y más.
¿Por qué es esto importante? Es posible crear un motor para el navegador web completamente nuevo, y siempre que se asegure de que el motor cumpla los estándares, dibujará las páginas web de una manera que coincida con el resto de navegadores web, para las miles de millones de páginas web. Esto significa que la “salsa secreta” para hacer que los sitios web funcionen no es un secreto perteneciente a un navegador. Los estándares permiten a los usuarios elegir el navegador web que satisfaga sus necesidades.
No más ley de Moore
Cuando los dinosaurios vagaban por la tierra y las personas solo tenían ordenadores de escritorio, era una suposición relativamente segura de que las computadoras se volverían más rápidas y potentes. Esta idea se baso en la Ley de Moore, una observación en la cual la cantidad de componentes (y por lo tanto la miniaturización / eficiencia de los chips de silicio) se duplicaría aproximadamente cada dos años. Increíblemente, esta observación fue válida hasta bien entrado el siglo XXI, y algunos argumentarán que sigue siendo válida en la vanguardia de la investigación actual. Entonces, ¿por qué la velocidad de un ordenador medio parece haberse estabilizado en los últimos 10 años?
La velocidad no es la única característica que los clientes buscan cuando compran un ordenador. Los ordenadores rápidos suelen consumir mucha energía, calentarse mucho y ser muy costosos. A veces, la gente quiere un ordenador portátil que tenga una buena duración de la batería. A veces, quieren un pequeño ordenador con pantalla táctil, con una cámara que quepa en el bolsillo y ¡que dure todo el día sin cargar! Los avances en informática lo han hecho posible (¡lo cual es increíble!), pero a costa de la velocidad bruta. Del mismo modo que no es eficiente (ni seguro) conducir tu coche lo más rápido posible, no es eficiente conducir tu ordenador lo más rápido posible. La solución ha sido tener múltiples “ordenadores” (núcleos) en un chip de CPU. No es raro ver teléfonos inteligentes con 4 núcleos más pequeños y menos potentes.
Lamentablemente, el diseño histórico del navegador web asumió esta trayectoria ascendente de velocidad. Además, escribir código que sea bueno usando múltiples núcleos de la CPU al mismo tiempo puede ser extremadamente complicado. Entonces, ¿cómo hacemos un navegador rápido y eficiente en la era de muchos ordenadores pequeños?
¡Tenemos algunas ideas!
En los próximos meses, analizaremos más detenidamente algunos de los cambios que llegarán a Firefox y cómo aprovecharán mejor el hardware moderno para ofrecer un navegador más rápido y estable que haga brillar los sitios web.

 es la solución ideal desarrollado en Java para aprendizajes, capacitaciones, adiestramientos, tutorías y reuniones. Elluminate Live
es la solución ideal desarrollado en Java para aprendizajes, capacitaciones, adiestramientos, tutorías y reuniones. Elluminate Live