

Para establecer la contraseña de acceso remoto para Anydesk solo debemos abrir un terminal como root y colocar lo siguiente:
echo XXXX | anydesk --set-password
Sustituya las XXXX por su contraseña, espero que esta información les sea útil, saludos.
Para establecer la contraseña de acceso remoto para Anydesk solo debemos abrir un terminal como root y colocar lo siguiente:
echo XXXX | anydesk --set-password
Sustituya las XXXX por su contraseña, espero que esta información les sea útil, saludos.
Para conocer el tiempo que lleva corriendo un proceso solo debemos ejecutar el siguiente comando:
ps -eo pid,etime,comm | grep firefox
En este ejemplo se escogió Firefox pero puede colocar el nombre de cualquier proceso del sistema y debería devolver una salida como esta:
10997 17:52 firefox
Donde podemos ver el PID (identificador del proceso) y el tiempo que lleva ejecutándose.
Espero que esta información les sea útil, saludos.

Hace un tiempo me toco generar un archivo XML para colocar en los teléfonos la agenda de contactos, para ello cree el script que les comparto hoy.
https://gitlab.com/sinfallas/issabel-agenda
Solo deben cambiar el nombre de usuario y la contraseña de su base de datos y el script hará el resto, saludos…

Muchas veces nos encontramos con que a la hora de clonar un repositorio desde Git mediante SSH este no utiliza el puerto por defecto y nos da error al ejecutar el comando clone, para corregir este error solo basta con ejecutar el comando de la siguiente forma:
git clone ssh://usuario@servidor.com:2222/ejemplo/proyecto.git
Espero que esta información les sea útil, saludos.
Una pregunta muy común entre usuarios de rsync es como evitar la copia de un archivo; para ello solo debemos agregar un parámetro al momento de ejecutar el comando:
rsync -avhn --exclude 'Thumbs.db' origen destino
En este ejemplo excluimos el archivo thumb.db pero puede sustituirse por cualquier archivo.
Espero que esta información les sea útil, saludos…
Este pequeño truco nos permite saber la IP publica de un equipo desde la linea de comandos, solo basta ejecutar el siguiente comando:
dig +short myip.opendns.com @resolver1.opendns.com
Una alternativa a dicho comando podría ser la siguiente:
dig TXT +short o-o.myaddr.l.google.com @ns1.google.com
Espero que esta información les sea útil, saludos…
Muchas veces necesitamos hacer algún script en bash donde queremos que tenga ciertas características, y muchas veces queremos que las salidas por pantalla de ese script se vean distintas para llamar la atención.
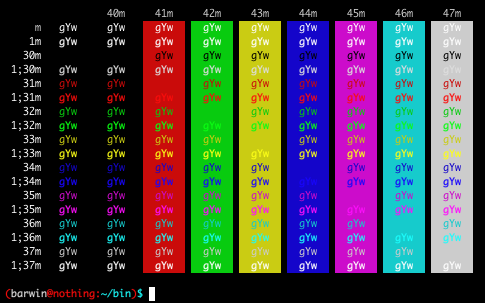
Pues bien, se puede usar colores para el texto en el bash de una forma sencilla.
Esta es la lista de algunos de los códigos de color para nuestro texto:
El comando echo se debe de ejecutar con el parámetro -e haciendo que bash interprete el comando \e (o sea el escape) de esta manera:
echo -e ‘Esto es \e[0;31mrojo\e[0m y esto es \e[1;34mazul resaltado\e[0m’
Resultado: Esto es rojo y esto es azul
echo -e ‘Así se escribe \e[1;34mG\e[0m\e[1;31mo\e[0m\e[1;33mo\e[0m\e[1;34mg\e[0m\e[1;32ml\e[0m\e[1;31me\e[0m’
Resultado: Así se escribe Google
En resumen para poder utilizarlo solo hay que poner los caracteres que quieras que tengan color entre los caracteres de escape de esta manera:
‘\e[CODIGOm(texto)\e[0m’ (el texto sin los paréntesis)
Colores de fondo
De la misma forma podemos cambiar el color de fondo mediante los siguientes valores:
Para utilizarlo solo debemos seguir la siguiente sintaxis:
echo -e "\e[42mMuestra\e[49m"
Como se puede apreciar en la imagen que acompaña este post las combinaciones pueden ser bastante grandes y solo hace falta un poco de creatividad para crear resultados llamativos. Cabe destacar que el código \e[49m regresa el color de fondo al original.
A veces no podemos utilizar nuestro servidor principal, ya que estamos cambiándolo, actualizándolo, peleándonos con dependencias o trabajando en configuración o plug-ins. Por lo que necesitamos algo para reemplazarlo momentáneamente.

Tampoco se quiere algo demasiado grande porque es para un apaño. Tal vez no tengamos nodeJs instalado, o python en los que nos podemos crear un servidor web con pocas líneas. Y tampoco queremos tener que instalar demasiadas cosas.
Como alternativa ligera podemos usar netcat el cual viene instalado por defecto en muchas distribuciones.
Sólo tenemos que ejecutar lo siguiente:
$ sudo -c sh 'while true; do nc -l -p 80 < respuesta.html; done'
Sin sudo y con usuario root si no disponemos de él en el sistema. Con esto, vamos a poner constantemente en escucha el puerto 80 y procesando todas las peticiones de la misma forma, devolviendo los contenidos de respuesta.html.
Las pruebas pueden realizarse como un usuario normal (no root) si utilizamos un puerto mayor de 1024, por ejemplo el 8000, 8080, 1234, etc:
$ while true; do nc -l -p 8000 < respuesta.html; done
Como la respuesta debe ser muy rápida, en principio no tenemos necesidad de algo más complicado (esperemos que no vengan demasiadas visitas mientras trabajamos). Pero este sistema no soportará usuarios concurrentes, recordemos que es sólo un servidor temporal y puede que a algún usuario le dé algún problema en conectar. Podemos guardar un registro de todo lo que ha pasado con:
$ sudo -c sh 'while true; do nc -l -p 80 < respuesta.html; done > log'
o como usuario:
$ while true; do nc -l -p 8000 < respuesta.html; done > log
Creando respuesta.html
Como habrás podido ver respuesta.html no es un archivo HTML normal, en realidad aquí hay que poner toda la respuesta completa (con cabeceras incluidas), podemos hacer algo sencillo primero:
HTTP/1.1 200 OK Server: LittleServer Content-Type: text/html;charset=UTF-8<html> <body> <h1>Lo sentimos, estamos de mantenimiento</h1> Disculpe las molestias, en un momento estaremos con usted. </body> </html>
La página a partir de la etiqueta <html>, podemos poner el código HTML que queramos. Aunque ahora estaremos contestando con un código de salida exitoso, lo que significa que los usuarios no se cabrearán (bueno sí, pero al menos verán una explicación), pero los buscadores y robots sí que la tomarán con nosotros, porque se creerán que ésta es la página buena, es más todas las páginas del servidor responderán lo mismo.
Respondiendo para que los buscadores no nos tengan en cuenta
Para ello tenemos que poner en nuestra cabecera un error 503 (Servicio no disponible). Esto será bueno porque no devolveremos un 200 (OK) para las páginas temporales, ni devolveremos un 404 (Not found / No encontrado) para el resto de páginas que no estén en nuestro servidor pero si deberán estar y el buscador de turno lo sabe (esto último sería horrible para nuestro posicionamiento, porque el buscador se creería que esas páginas ya no existen y las desindexará).
Para ello, nuestro archivo de respuesta.html será el siguiente:
HTTP/1.1 503 Service Unavailable Server: Maintenance Retry-After: 3600 Content-Type: text/html;charset=UTF-8<html> <body> <h1>Lo sentimos, estamos de mantenimiento</h1> Disculpe las molestias, en un momento estaremos con usted. </body> </html>
Además, añadiremos Retry-After para que vuelvan dentro de un rato a ver si todo está bien. No se garantiza que los buscadores vuelvan dentro de una hora (3600 segundos), pero es normal que vuelvan cuando tengan un rato después de una hora.
Queremos complicarnos la vida
Si has llegado hasta aquí, eres de los que le gustan complicarse la vida e inventar cosas, así que, para dejar un poco a la imaginación y para hacer un servidor web un poco más completo.
Vamos a crear un script que procesará la petición HTTP que se realice (tenemos que recordar que cuantas más cosas metamos, más vulnerable será nuestro sistema, y un script aquí es tremendamente vulnerable).
dispatcher.sh
#!/bin/bash
I=0
while read RAWINPUT; do
if [ ${#RAWINPUT} -le 1 ]
then
break
fi
INPUT[$I]=$RAWINPUT
I=$(($I+1))
doneread -a FIRSTLINE <<< ${INPUT[0]}
METHOD=${FIRSTLINE[0]}
REQUEST=${FIRSTLINE[1]}
HTTPVER=${FIRSTLINE[2]}
echo $HTTPVER 503 Service Unavailable
echo "Retry-After: 3600"
echo "Server: Bash-Maintenance"
case "$REQUEST" in
"/logo.jpg")
FILE="my-logo-file.jpg"
echo "Content-Type: image/jpeg"
echo "Content-Length: "$(stat -c%s "$FILE")
echo
cat $FILE
;;
"/fortune")
CONTENT=$(fortune)
echo "Content-Type: text/html; charset=utf-8"
echo "Content-Length: "${#CONTENT}
echo
echo $CONTENT
;;
*)
FILE="respuesta.html"
echo "Content-Type: text/html; charset=utf-8"
echo "Content-Length: "$(stat -c%s "$FILE")
echo
cat $FILE
;;
esac
Ahora tenemos 3 respuestas posibles:
Para hacer que netcat utilice este archivo, depende de la versión, por un lado podemos llamar a:
$ sudo sh -c 'while true; do nc -v -l -p 80 -c dispatcher.sh; done'
como usuario:
$ while true; do nc -v -l -p 8000 -c dispatcher.sh; done
Aunque en muchas versiones de GNU/Linux viene otra versión instalada que no soporta -c, pero no todo está perdido:
$ rm /tmp/bashwebtmp; mkfifo /tmp/bashwebtmp; sudo -c sh 'while true; do cat /tmp/f | bash dispatcher.sh | nc -v -l -p 80 > /tmp/f; done';
como usuario:
$ rm /tmp/bashwebtmp; mkfifo /tmp/bashwebtmp; while true; do cat /tmp/f | bash dispatcher.sh | nc -v -l -p 8000 > /tmp/f; done;
No debemos olvidar borrar la pipe /tmp/bashwebtmp cuando terminemos de usar el programa.
Una cosa más, no debemos abusar de este script y no debemos enviar contenidos muy grandes, por ejemplo, no abusar de las imágenes, como decía antes, sólo soporta una conexión, si hacemos que esta conexión se extienda en el tiempo perderemos capacidad de atender más conexiones.
Visto en: Poesía Binaria
En estos días me toco recuperar mi VPS vía consola remota, al revisar el /var/log/messages me di cuenta de el Out of Memory Killer (OOM Killer) había hecho de las suyas al quedarse sin memoria. Luego de analizar detenidamente los logs y me di cuenta que fue una combinación de factores, Google, Yahoo y Yandex me estaban indexando tanto este blog como unos foros de autos que alojo en este servidor al mismo tiempo.
El script para descargar torrents estaba corriendo al igual que el torrent tracker y alguien me estaba haciendo flood vía IRC en freenode puede había dejado irssi conectado.
El OOM Killer tiene un algoritmo que decide que procesos son los mejores para aniquilar sin embargo es posible manipular estos valores y dejarle saber al OOM Killer que procesos prefieres que mate primero. Para automatizar esta tarea hice un script que nos ayudara con esta tarea:
for programas in SCREEN irssi top
do for pid_of_oomk_candidate in `pidof -x $programas`
do echo 10 > /proc/$pid_of_oomk_candidate/oom_adj
done
done
Como ven el script anterior agrega 10 al OOMK score a los procesos que menos me interesan permanezcan vivos cuando me quede sin memoria mientras que el siguiente hará exactamente lo contrario, mantendrá vivo un poco mas estos procesos:
for programas in mysqld portsentry iptables
do for pid_of_oomk_candidate in `pidof -x $programas`
do echo -5 > /proc/$pid_of_oomk_candidate/oom_adj
done
done
echo -17 > /proc/`pidof -s sshd`/oom_adj
En este ultimo mysql portsentry y iptables tendrán cinco puntos de ventaja en relación con el resto de los candidatos y si se fijan en la ultima linea estamos asegurándonos que sshd no sea candidato bajo ninguna circunstancia.
Ahora unifiquemos estos dos scripts y demosle un poco mas de flexibilidad, estoy seguro que hay gente que prefiere asignarle a irssi un valor distinto de screen. Lo primero que necesitaremos es un script de configuración, vamos crearlo en /etc/candidatos_oomk.conf y el contenido se debería de ver algo así:
# Programas que queremos sacrificar, entre mas alto el valor
# mas peso tienen en la lista de candidatos.
irssi 4
SCREEN 3
smtpd 2
apache2 1
# Programas que queremos salvar, estos tendrán valores negativos
portsentry -2
mysqld -5
sshd -17
El script al que le puse de nombre oomk_adj_candidatos.sh se veria algo asi:
#!/bin/bash
CONFIGURACION="/etc/candidatos_oomk.conf"
while read programas
do proceso=`echo $programas |grep -v \# | grep [0-9]$| awk '{print $1}'`
ajuste=`echo $programas |grep -v \# | grep [0-9]$| awk '{print $2}'`
if [ -z "$proceso" ] then
continue
else
echo $proceso
for pids_proceso in `/bin/pidof $proceso`
do echo " echo $ajuste > /proc/$pids_proceso/oom_adj"
done
fi done < $CONFIGURACION
El script es simple, leemos el archivo de configuracion linea por linea separamos el nombre del proceso del ajuste que le vamos a hacer guardando cada valor en las variables $proceso y $ajuste. Evaluamos si la variable $proceso esta vacía, y de ser así seguimos con la próxima linea, de lo contrario continuamos procesando esa misma linea. Obtenemos el PID del proceso usando pidof y para cada PID vamos escribir el valor de $ajuste en su archivo oom_adj dentro de /proc.
Pueden colocar este script en su /etc/rc.local o en un cronjob y recuerden que si quieren consultar la lista de candidatos y ver como están sus scrores o saber un poco mas del tema, pueden consultar este articulo: El OOM Killer y manipulación de candidatos.
Mas de una vez he intenten ejecutar sl cuando intentan ejecutar ls para listar archivos y directorios, es un error que todos cometemos pero ¿que pasaria si sl en realidad fuese un comando?. Afortunadamente para nuestro entretenimiento hay una aplicación de nombre sl y consiste en un tren ascii que sale en el terminal cada vez al momento de ejecutar sl. Perfecto para una broma practica, instalarlo en un servidor que muchas personas usan y esperar a escuchar los cuentos.
Aquí les dejo un video que muestra como instalarlo y como se ve al momento de ejecutarlo.
En caso de que no puedas ver el video, puedes instalar esta aplicación ejecutando:
su - yum install -y sl
Como ven es inofensivo, o por lo menos menos inofensivo que un ualias a rm -Rf /*, de hecho un compañero de trabajo fue el que me comento sobre esta broma practica. La aplicación sl esta disponible para OSX a través del manejador de paquetes brew.
{kind=link}