Hace unos días durante una entrevista de trabajo observe como las personas tienden a pensar que contratar a un informático significa que este puede y debe hacer todo lo relacionado con computadoras dentro de la organización, lo cual nos llevas a sobrecargas de trabajo e incumplimiento de fechas de entrega.
Para aclarar un poco el panorama decidí escribir este post con algunas definiciones que considero importantes:
Front-end y Back-end: Son términos que se refieren a la separación de intereses entre una capa de presentación y una capa de acceso a datos, respectivamente. Pueden traducirse al español el primero como interfaz, frontal final o frontal y el segundo como motor, dorsal final o zaga, aunque es común dejar estos términos en inglés.
En diseño de software el front-end es la parte del software que interactúa con los usuarios y el back-end es la parte que procesa la entrada desde el front-end. La separación del sistema en front-ends y back-ends es un tipo de abstracción que ayuda a mantener las diferentes partes del sistema separadas. La idea general es que el front-end sea el responsable de recolectar los datos de entrada del usuario, que pueden ser de muchas y variadas formas, y los transforma ajustándolos a las especificaciones que demanda el back-end para poder procesarlos, devolviendo generalmente una respuesta que el front-end recibe y expone al usuario de una forma entendible para este. La conexión del front-end y el back-end es un tipo de interfaz.
En diseño web (o desarrollo web) hace referencia a la visualización del usuario navegante por un lado (front-end), y del administrador del sitio con sus respectivos sistemas por el otro (back-end).
DBA: Un administrador de bases de datos (también conocido como DBA, en inglés database administrator) es aquel profesional que administra las tecnologías de la información y la comunicación, siendo responsable de los aspectos técnicos, tecnológicos, científicos, inteligencia de negocios y legales de bases de datos, y de la calidad de datos.
Sus tareas incluyen las siguientes:
- Implementar, dar soporte y gestionar bases de datos corporativas.
- Crear y configurar bases de datos relacionales.
- Ser responsables de la integridad de los datos y la disponibilidad.
- Diseñar, desplegar y monitorizar servidores de bases de datos.
- Diseñar la distribución de los datos y las soluciones de almacenamiento.
- Garantizar la seguridad de las bases de datos, realizar copias de seguridad y llevar a cabo la recuperación de desastres.
- Planificar e implementar el aprovisionamiento de los datos y aplicaciones.
- Diseñar planes de contingencia.
- Diseñar y crear las bases de datos corporativas de soluciones avanzadas.
- Analizar y reportar datos corporativos que ayuden a la toma de decisiones en la inteligencia de negocios.
- Producir diagramas de entidades relacionales y diagramas de flujos de datos, normalización esquemática, localización lógica y física de bases de datos y parámetros de tablas.
El control de tecnologías de bases de datos y las matemáticas permite al DBA rendir informes, realizar reportes sobre cualquier proceso industrial y participar de forma activa en procesos avanzados de desarrollo, consolidando las capacidades propias de un profesional de tecnologías de la información y un ingeniero especialista.
Sysadmin: Un Administrador de sistemas es la persona que tiene la responsabilidad de implementar, configurar, mantener, monitorizar, documentar y asegurar el correcto funcionamiento de un sistema informático, o algún aspecto de éste.
El administrador de sistemas tiene por objeto garantizar el tiempo de actividad (uptime), rendimiento, uso de recursos y la seguridad de los servidores que administra de forma dinámica.
En las organizaciones que cuentan con diversos sistemas informáticos, se torna más compleja la administración. De esta forma, las funciones del administrador de sistemas se dividen en roles: administrador de servidores, de bases de datos, de redes, de correo electrónico, de servidores web, de seguridad, de respaldo etc. Cada uno con sus correspondientes tareas específicas.
En muchas organizaciones, la tarea de un Administrador de Sistemas se extiende a la planificación de crecimiento de cada sistema, como también la importante tarea de copia de respaldo de la información contenida en ellos.
Netadmin: Los administradores de red son básicamente el equivalente de red de los administradores de sistemas: mantienen el hardware y software de la red.
Esto incluye el despliegue, mantenimiento y monitoreo del engranaje de la red: switches, routers, cortafuegos, etc. Las actividades de administración de una red por lo general incluyen la asignación de direcciones, asignación de protocolos de ruteo y configuración de tablas de ruteo así como, configuración de autenticación y autorización de los servicios.
Frecuentemente se incluyen algunas otras actividades como el mantenimiento de las instalaciones de red tales como los controladores y ajustes de las computadoras e impresoras. A veces también se incluye el mantenimiento de algunos tipos de servidores como VPN, sistemas detectores de intrusos, etc.
Los analistas y especialistas de red se concentran en el diseño y seguridad de la red, particularmente en la resolución de problemas o depuración de problemas relacionados con la red. Su trabajo también incluye el mantenimiento de la infraestructura de autorización a la red.
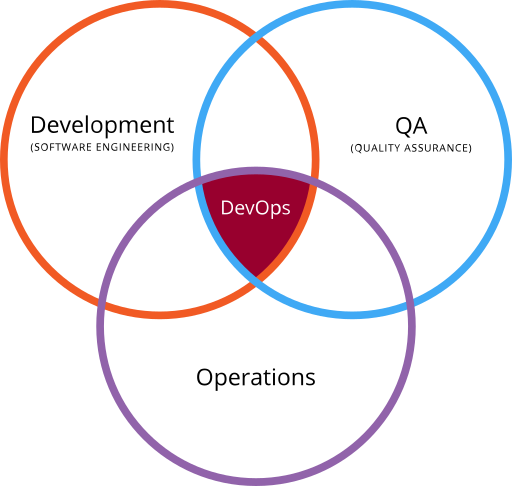
Devops: es un acrónimo inglés de development (desarrollo) y operations (operaciones), que se refiere a una cultura o movimiento centrado en la comunicación, colaboración e integración entre desarrolladores de software y los profesionales en las tecnologías de la información (IT). Automatiza el proceso de entrega del software y los cambios en la infraestructura. Su objetivo es ayudar a crear un entorno donde la construcción, prueba y lanzamiento de un software pueda ser más rápido y con mayor fiabilidad.
Las empresas con entregas (releases) muy frecuentes podrían requerir conocimientos de DevOps. Flickr desarrolló un sistema DevOps para cumplir un requisito de negocio de diez despliegues al día. A este tipo de sistemas se les conoce como despliegue continuo (continuous deployment) o entrega continua (continuous delivery), y suelen estar asociados a metodologías lean startup.