Trabajando con Ruby On Rails me ha tocado escribir código usando HAML. Particularmente no me agrada mucho (entre otras cosas porque no tiene soporte multilínea, porque no identa correctamente las cadenas de texto plano, porque agrega otra capa más de interpretación a la aplicación, etc) pero cuando toca usarlo es bueno hacerlo con un buen soporte. Y cuando hablo de soporte me refiero al resaltado de sintaxis.
Para escribir código usualmente uso un editor de texto (Gedit o Geany), así que en ésta receta explicaré como agregar soporte para el resaltado de sintaxis en Gedit.
Primero agregamos soporte para que las extensiones usadas comúnmente en Rails sean reconocidas por el sistema. Abrimos una terminal y escribimos:
Luego agregamos los archivos de definición de sintaxis en la carpeta del sourceview de GTK ejecutando:
Ahora con nuestro editor de texto favorito (y como root) abrimos el archivo /usr/share/gtksourceview-2.0/language-specs/ruby.lang para modificar el sourceview de GTK y agregar soporte para nuevas extensiones. Buscamos la línea:
Y la cambiamos por:
Por último, abrimos el archivo /usr/share/gtksourceview-2.0/language-specs/html.lang y buscamos la línea que dice:
Y la cambiamos por:
Cerramos todas las instancias de Gedit y al abrir de nuevo ya nuestro código HAML debería verse resaltado.
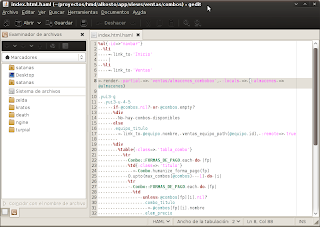
Existen recetas que instalan una serie de plugins (con soporte para haml, rjs, etc) y te dejan al Gedit como TextMate, pero como no me gusta TextMate entonces prefiero hacerlo a patica xD
Espero que la receta les haya servido de ayuda.
Referencias:
http://groups.google.com/group/haml/browse_thread/thread/6c8babd81a46b6b8/b5100d80d9182c71?pli=1
http://blog.adsdevshop.com/2008/04/19/erb-syntax-highlighting-in-gedit/
Para escribir código usualmente uso un editor de texto (Gedit o Geany), así que en ésta receta explicaré como agregar soporte para el resaltado de sintaxis en Gedit.
Primero agregamos soporte para que las extensiones usadas comúnmente en Rails sean reconocidas por el sistema. Abrimos una terminal y escribimos:
wget http://dl.dropbox.com/u/16349833/rails.xml
sudo cp rails.xml /usr/share/mime/packages/rails.xml
sudo update-mime-database /usr/share/mimeLuego agregamos los archivos de definición de sintaxis en la carpeta del sourceview de GTK ejecutando:
wget http://dl.dropbox.com/u/16349833/gedit_rails_syntax.zip
sudo unzip gedit_rails_syntax.zip -d /usr/share/gtksourceview-2.0/language-specsAhora con nuestro editor de texto favorito (y como root) abrimos el archivo /usr/share/gtksourceview-2.0/language-specs/ruby.lang para modificar el sourceview de GTK y agregar soporte para nuevas extensiones. Buscamos la línea:
*.rb Y la cambiamos por:
*.rb;*.rake;*.rjs Por último, abrimos el archivo /usr/share/gtksourceview-2.0/language-specs/html.lang y buscamos la línea que dice:
*..html;*.htm Y la cambiamos por:
*.html;*.htm;*.erb;*.rhtml Cerramos todas las instancias de Gedit y al abrir de nuevo ya nuestro código HAML debería verse resaltado.

Existen recetas que instalan una serie de plugins (con soporte para haml, rjs, etc) y te dejan al Gedit como TextMate, pero como no me gusta TextMate entonces prefiero hacerlo a patica xD
Espero que la receta les haya servido de ayuda.
Referencias:
http://groups.google.com/group/haml/browse_thread/thread/6c8babd81a46b6b8/b5100d80d9182c71?pli=1
http://blog.adsdevshop.com/2008/04/19/erb-syntax-highlighting-in-gedit/